Biodentify
Our patented technology – developed to analyze surface soil or seabed samples (few mm3’s from approx. 1 ft. depth) – recognizes otherwise undetectable hydrocarbon micro-seepage from prospective areas.
After the sample has been taken, first bacterial DNA is extracted from this sample, producing tagged 16S rDNA data that is translated into bacterial species.
The result of this analysis is hundreds of thousands (partly field type specific) biomarkers. The ‘DNA fingerprint’ of the soil sample.
Our database – with over 2,500 samples from both onshore and offshore locations, detailed ‘DNA fingerprints’, with related production data on biomarkers – is subsequently used as modeling input to our proprietary localized triple loop © computational model.
Our trained model is capable of predicting the presence of a highly productive zone within a heterogeneous shale play, with an accuracy of >70% prior to drilling. For conventional plays, both on- and offshore, it is able to predict whether a prospect or well target location shows signs of hydrocarbons in the subsurface.
Our model basically uses the difference in DNA finger-prints that are connected to highly productive areas and those correlated to unproductive (or dry) areas or locations.
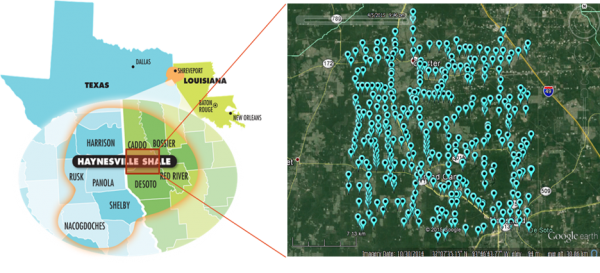
Six plays in the US are extensively sampled, with different characteristics on productivity, the age of the producing interval, type of play (oil vs gas), geology and climate and soil type: Bone Spring (Permian), Bakken, Antrim, Avalon, Lewis, Haynesville ,and Marcellus. In addition studies have been carried out both on- and offshore the Netherlands as well as offshore Norway.
Rating
Visits
702
Redirects
147
Don't Miss Out! Get the Best Deal on this Software - Email Us Now!